The goal of kumquat is to be a smaller simpler implementation of LIME. This is purely for demonstration purposes, and is not ideal to be used in production settings.
Kumquat is super easy to use. First you get your data set up and your model set up. Then you decide the data points of interest and kumquat will give you a list of information for each point you selected.
Below we will go through a step-by-step guide on setting up kumquats to be used.
Installation
You can install the development version of kumquat like so:
pak::pak("janithwanni/kumquat")You can install the CRAN release of kumquat by running:
install.packages("kumquat")Limitations
- Currently
kumquatonly supports datasets of two numeric variables and one categorical variable.
Usage
Step 1: Load Data
library(tidyverse)
#> ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.2.1 ✔ readr 2.2.0
#> ✔ forcats 1.0.1 ✔ stringr 1.6.0
#> ✔ ggplot2 4.0.3 ✔ tibble 3.3.1
#> ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
#> ✔ purrr 1.2.2
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(colorspace)
data(d_vertical)
ggplot(d_vertical, aes(x = x, y = y, colour = class)) +
geom_point() +
scale_colour_discrete_divergingx(palette = "Zissou 1") +
theme_minimal() +
theme(aspect.ratio = 1)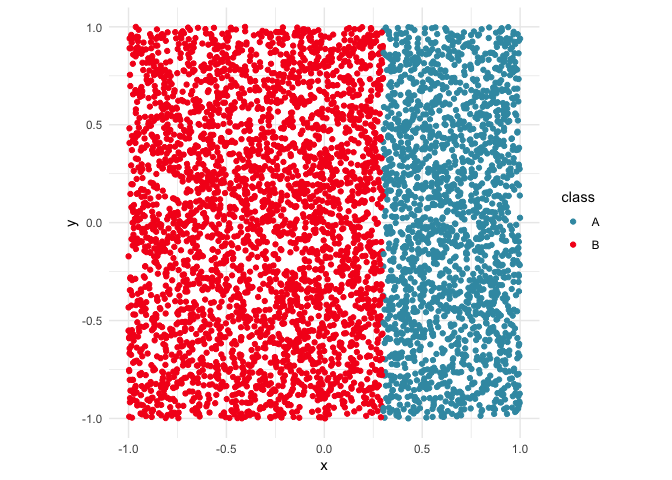
Step 2: Bundling the model
When setting up the model, kumquat expects a bundle object containing the model and its reference pointers.
library(randomForest)
#> randomForest 4.7-1.2
#> Type rfNews() to see new features/changes/bug fixes.
#>
#> Attaching package: 'randomForest'
#> The following object is masked from 'package:dplyr':
#>
#> combine
#> The following object is masked from 'package:ggplot2':
#>
#> margin
library(bundle)
# Get model ready
rfmodel <- randomForest(
class ~ x + y,
data = d_vertical
)
# Bundle model up
rfmodel_bundled <- bundle(rfmodel)Step 3: Decide on points of interest
# Decide on points of interest
find_closest <- function(pt, data) {
dst <- data |>
mutate(dst = sqrt((x - pt$x)^2 + (y - pt$y)^2))
return(which.min(dst$dst))
}
pois <- c(
# Case 1: the point of interest is not near the boundary
find_closest(tibble(x=0, y=0), d_vertical),
# Case 2: the point is on the decision boundary
find_closest(tibble(x=0.3, y=0.5), d_vertical)
)
ggplot(d_vertical, aes(x = x, y = y, colour = class)) +
geom_point() +
geom_point(data=d_vertical[pois, ], mapping=aes(x=x,y=y,fill=class), shape = 18, color = "black") +
scale_colour_discrete_divergingx(palette = "Zissou 1") +
theme_minimal() +
theme(aspect.ratio = 1)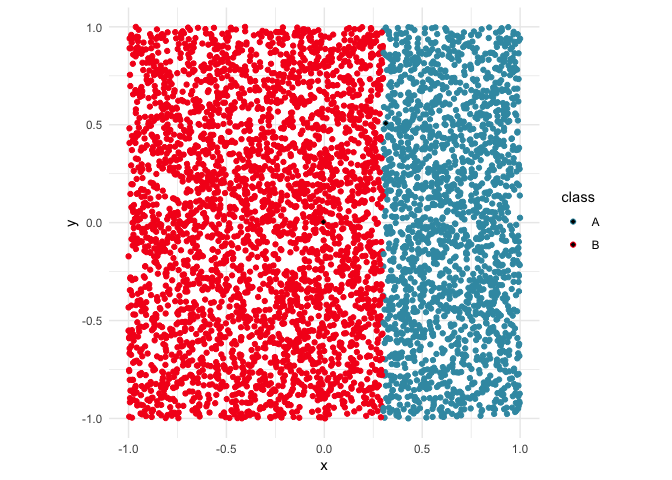
Step 5: Examine the outputs
Case 1: The point is not near the decision boundary
In this case, according to ks[[1]]$local_model$importances both x and y are equally important.
# str(ks)
ks[[1]]
#> $perturbations
#> # A tibble: 441 × 3
#> x y pred
#> <dbl> <dbl> <fct>
#> 1 -0.105 -0.0966 B
#> 2 -0.105 -0.0866 B
#> 3 -0.105 -0.0766 B
#> 4 -0.105 -0.0666 B
#> 5 -0.105 -0.0566 B
#> 6 -0.105 -0.0466 B
#> 7 -0.105 -0.0366 B
#> 8 -0.105 -0.0266 B
#> 9 -0.105 -0.0166 B
#> 10 -0.105 -0.00659 B
#> # ℹ 431 more rows
#>
#> $local_model
#> $local_model$glm_predictions
#> 1
#> B
#> Levels: A B
#>
#> $local_model$importances
#> x y
#> 0.5 0.5
#>
#> $local_model$model
#> NULL
#>
#>
#> $point_of_interest
#> [1] 912
#>
#> $train_data
#> # A tibble: 5,000 × 4
#> x y class pred
#> <dbl> <dbl> <fct> <fct>
#> 1 0.885 0.615 A A
#> 2 -0.264 0.649 B B
#> 3 0.190 0.197 B B
#> 4 -0.752 -0.749 B B
#> 5 -0.817 0.661 B B
#> 6 0.533 -0.305 A A
#> 7 0.695 0.154 A A
#> 8 0.143 -0.300 B B
#> 9 -0.647 -0.795 B B
#> 10 0.300 0.739 B B
#> # ℹ 4,990 more rowsCase 2: The point is near the decision boundary
In this case, according to ks[[2]]$local_model$importances, x has an importance of -1000.3018471 and y has an importance of 0. Since the decision boundary was made using just the x variable we would expect the x variable to be more important in the model’s decision making process.
# str(ks)
ks[[2]]
#> $perturbations
#> # A tibble: 441 × 3
#> x y pred
#> <dbl> <dbl> <fct>
#> 1 0.214 0.408 B
#> 2 0.214 0.418 B
#> 3 0.214 0.428 B
#> 4 0.214 0.438 B
#> 5 0.214 0.448 B
#> 6 0.214 0.458 B
#> 7 0.214 0.468 B
#> 8 0.214 0.478 B
#> 9 0.214 0.488 B
#> 10 0.214 0.498 B
#> # ℹ 431 more rows
#>
#> $local_model
#> $local_model$glm_predictions
#> [1] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [19] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [37] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [55] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [73] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [91] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [109] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [127] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [145] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [163] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
#> [181] "B" "B" "B" "B" "B" "B" "B" "B" "B" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [199] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [217] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [235] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [253] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [271] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [289] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [307] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [325] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [343] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [361] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [379] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [397] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [415] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
#> [433] "A" "A" "A" "A" "A" "A" "A" "A" "A"
#>
#> $local_model$importances
#> x y
#> -1000.302 0.000
#>
#> $local_model$coef_mat
#> lambda.min
#> (Intercept) 298.9126
#> x -1000.3018
#> y 0.0000
#>
#> $local_model$model
#>
#> Call: glmnet::cv.glmnet(x = X, y = y, nfolds = nfolds, family = "binomial", alpha = alpha)
#>
#> Measure: Binomial Deviance
#>
#> Lambda Index Measure SE Nonzero
#> min 5.115e-05 98 0.001352 0.0001798 1
#> 1se 5.614e-05 97 0.001479 0.0001968 1
#>
#>
#> $point_of_interest
#> [1] 1915
#>
#> $train_data
#> # A tibble: 5,000 × 4
#> x y class pred
#> <dbl> <dbl> <fct> <fct>
#> 1 0.885 0.615 A A
#> 2 -0.264 0.649 B B
#> 3 0.190 0.197 B B
#> 4 -0.752 -0.749 B B
#> 5 -0.817 0.661 B B
#> 6 0.533 -0.305 A A
#> 7 0.695 0.154 A A
#> 8 0.143 -0.300 B B
#> 9 -0.647 -0.795 B B
#> 10 0.300 0.739 B B
#> # ℹ 4,990 more rowsThe output from kumquat will be a list containing the following elements.
perturbations: A data.frame of perturbations used to fit the local model
local_model: Details of the glmnet model fit. This is also a list containing the following elements. In the case where the point of interest is not near the model’s decision boundary, the
modelcomponent will be NULL and the importances will be distributted equally.glm_predictions
importances: The importances of each feature
coef_mat: The coefficients
model: the glm_net model object
point_of_interest
train_data